Context & Scope
Kadeck is architected as a cloud-native system designed to scale flexibly alongside your Apache Kafka infrastructure. From a single-container deployment to a fully clustered configuration, it supports millions of data streams and multiple clusters—while preserving a deliberately small operational footprint.
Components
Kadeck
Kadeck serves as the central control plane for distributed real-time data systems. It connects to Apache Kafka clusters and related components to unify access, governance, and operations across teams and environments. Users interact with Kadeck through a web-based interface.
Context
Kadeck runs entirely within your controlled infrastructure—whether in private cloud, on-premise data centers, or containerized environments on public cloud platforms. The diagram below outlines the core components of the system and the external systems and actors that interface with it.
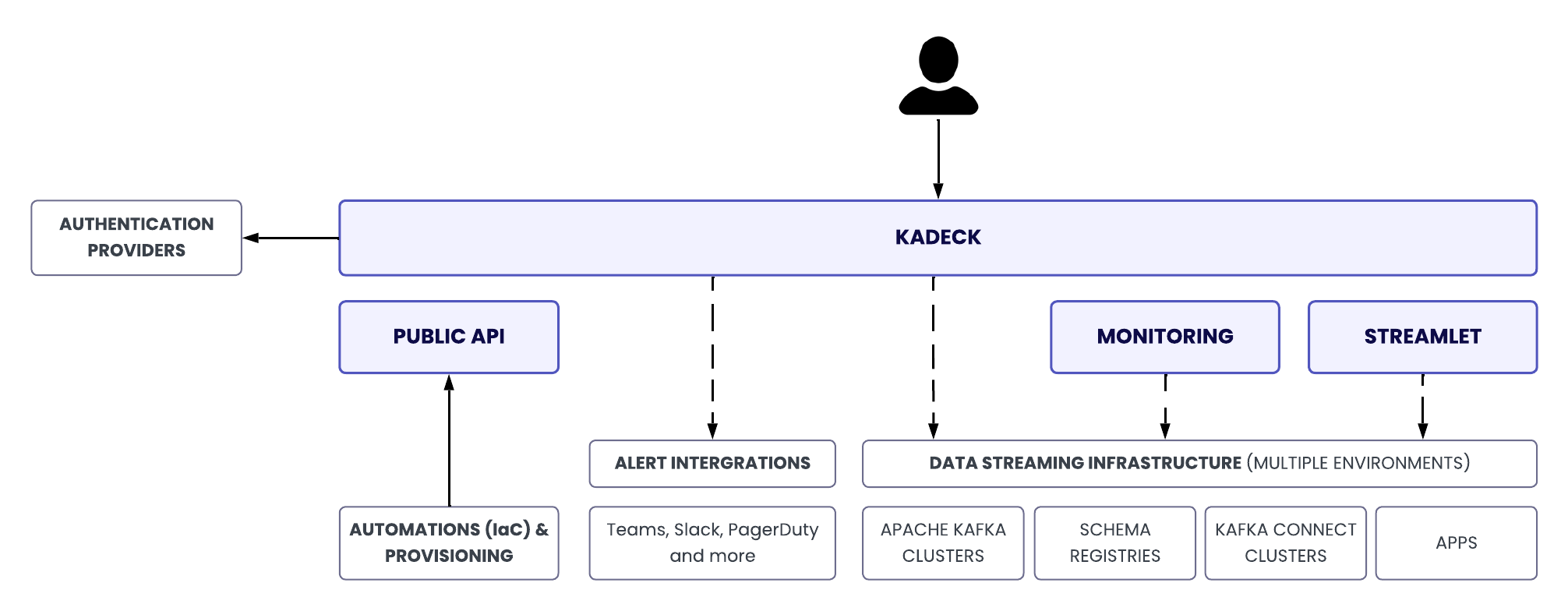
A single Kadeck setup typically connects to multiple, separate data streaming environments—each with its own Kafka clusters, Schema Registries, Connect clusters, and associated applications. This multi-environment architecture supports hybrid setups and allows organizations to centralize governance, monitoring, and control across all streaming domains from one unified platform.
Key external integrations include:
- Authentication providers (e.g., LDAP, OpenID)
- Automation and provisioning systems (IaC, CI/CD)
- Alerting and messaging platforms
- Public APIs for integration with internal tooling and workflows